
十年前,一位欧洲院士对我说:“东说念主工智能有不下百个细分赛说念,好意思国会界说一到两个流行赛说念海外呦呦,尔后全球创业者投资东说念主一哄而起去追逐这一两个赛说念。”
此后十年风口轮转,东说念主工智能从非共鸣到小共鸣,从小共鸣到大共鸣,却从未跳出这句话。
此次对话Serge,始于对他两年前参与撰写的论文《寻找不可证伪声明中的结构》的意思。只能惜这篇著述于今实在无东说念主问津,GoogleScholar援用量唯有2次。
这让东说念主诧异。
“甲子光年”认为,这篇论文被严重低估了。
事理一,这篇著述面对的问题极其要津(社交媒体不可证伪性数据的潜在叙事);
事理二,这篇著述给出了要紧的表面创新(三元标注法与SNaCK集结);
事理三,这篇著述给出了工程上的实行后果(数据集构建与缜密施行比对)。

论文作者PeterEbertChristensen、FrederikWarburg、MenglinJia和SergeBelongie;ARXIV2022
这篇论文不难领会,咱们从可证伪性这个看法脱手先容。
可证伪性(falsifiability)又称可反驳性(refutability)。科学形而上学常常使用严格的证伪法来判别一个表面是否科学,即“这些论断必须应允逻辑上的反例的存在”。
卡尔·波普尔在1934年建议,如若一个表面或假定不错被现存时刻的实证测验在逻辑上拒抗,那么它即是可证伪的。而如若一个抒发见缝就钻,以至于让天下莫得置喙余步,那常常只能让统共东说念主盛气凌人,对鼓吹科学进展有害。
科学家们能够或应该筹划的问题,或多或少要有罩门,即让别东说念主有契机袭击致使推翻。可证伪性的主见,是使表面具有瞻望性和可测试性,从而在实行中有用。
Serge的论文《寻找不可证伪声明中的结构》探讨了社交媒体上不可证伪声明的解读复杂性。
论文轻率:
社交媒体平台充斥着多数帖子和挑剔,许多主张无法被证伪。关联词,事实核查用具不及、社交麇集商议缺少结构、叙事识别存在艰巨、大众商议缺少质地等,形成诸多困扰。
论文筹划了如安在社交媒体上识别和领会那些无法被证伪的主张(unfalsifiableclaims),并将这些主张归纳为有限几种叙事(narratives),以便更好地促进社交媒体上的商议和诡辩。
真谛的是,作者构建了一个名为PAPYER的数据集,包含针对大众洗手间的干手步地(纸巾与空气干燥器)的诡辩,600个漫笔本摘抄,31种叙事,4个超等类别,以领会和发刻下方商议中的主流叙事。
该论文引入了一种超越现存事实核查时刻才调的新方法,为经管和领会数字通讯环境中不可证伪声明的影响提供了要紧孝顺——使用这个历程不错发现主流叙事,而且标明这个历程的阐扬突出了最近的大尺寸变换模子和最先进的无监督主题模子。
通过施行,作者发现使用当代句子调养器(如T5模子)进行驱动句子镶嵌是要津。他们还发现,采样策略对于生成高质地的镶嵌至关要紧,至极是“Distance-Rnd”策略阐扬最好。
施行扫尾标明,结合东说念主类疑望的三元组(triplets)不错揭示效用结晶叙事的真谛聚类。

仅2次援用
“甲子光年”认为,这篇论文在业界于今缺少关注的可能原因包括不限于:
(1)表面分析相对单薄,施行扫尾分析停留于定性(11页正文仅半页公式);
(2)对于用来作念对比的几个算法实在莫得伸开先容;
(3)该范围可能还莫得学术界调处的数据集,导致在学术界里面莫得“出圈”;
(4)笔者强调了T5的要津性,但莫得阐发明晰其算法优厚性。

天然上述论文鲜为东说念主知,但Serge本东说念主是计较机视觉和机器学习范围极具影响力的科学家,主要筹划对象识别和图像分割,他千般论文援用总量为178971万次。
SergeBelongie,哥本哈根大学(UniversityofCopenhagen)计较机学说明注解、丹麦东说念主工智能前卫中心(TheDanishPioneerCentreforArtificialIntelligence)主任。此前,他曾任康奈尔科技学院副院长和AndrewH.和AnnR.Tisch计较机科学说明注解。
最值得先容的,是Serge是MSCOCO的主要作者。
MSCOCO数据集是最知名的计较机视觉大范围数据集之一。2000年,Serge与JitendraMalik(现加州大学伯克利分校计较机科学系说明注解,计较机视觉范围知名学者)共同建议了“体式高下文”(ShapeContext)看法,是计较机视觉和对象识别范围期骗十分平常的体式特征形容方法。
2004年,Serge被《麻省理工学院时刻挑剔》评为35岁以下的后生科技创新者;2007年,他和JitendraMalik获取了马尔奖荣誉提名;2015年,Serge获取了ICCV亥姆霍兹奖,该奖项主要颁发给在计较机视觉范围作念出根人性孝顺的论文作者。
Serge照旧多家公司的合资创始东说念主,包括DigitalPersona(2014年与CrossMatch合并)、CarCode(被TransportDataSystems收购)、AnchoviLabs(2012年被Dropbox收购)和Orpix。
刻下,Serge团队正在开拓社交麇集分析的全新维度——从此前未被关注的,不得手脚念传统事实核查的多数琐碎言论切入,分析社交麇集上的议题竖立和“叙当事人宰”。
这在当下时刻节点尤有很是道理:
天下反法西斯构兵后,非论时刻冲破和瓶颈轮流,王人跟着时刻在历史画卷中放诞激荡地推移。如同在时空坐标系中伸开的《辉煌上河图》,充斥着千万种光景和古今众生相。
以下为甲姑娘对话Serge。
一、可证伪性正在接纳挑战
筹划东说念主员在实行中泛泛会受到他们可爱或不可爱的阐发的影响——有点雷同于Instagram上的热点话题。
高跟美女甲姑娘:“弗成证伪,不成科学”已成为一个科学界的广博共鸣。但许多形而上学家对此建议了质疑,认为可证伪性原则可能导致科学争论变得永无至极。可证伪性是否是科学逾越的必要条目?
Serge:把柄流行的不雅点,一个科学表面必须是可证伪的。
甲姑娘:这是流行的不雅点,但可证伪性是当卑鄙行的范式吗?
Serge:机器学习文件在往时15年出现了爆炸式增长,每天王人有多数论文发表、援用。在这些论文中,干系工作的部分常常会援用其他文件,但援用的未必是与其工作最干系的文件。这是因为文件数目强大,筹划东说念主员本色上是在讲演该范围的主导阐发。
咱们泛泛认为我方是卡尔·波普尔传统中的科学家,只受可证伪断言的影响。关联词,科学筹划也有潮水,比如生成回击生成麇集和Transformers等时刻。尽管这些论文的筹备是罢黜科学传统,筹划东说念主员在实行中泛泛会受到他们可爱或不可爱的阐发的影响——有点雷同于Instagram上的热点话题。
甲姑娘:你的意思是,机器学习以来,科学家脱手背离可证伪性的设施?
Serge:科学家们常常会宣称我方不受这些影响,认为我方是客不雅的,但他们毕竟是东说念主类,会被这些流行的不雅点所左右。这是咱们认为不科学的东西,更多的是直观和不雅点。
甲姑娘:你若何界说社交媒体中的不可证伪声明?
Serge:咱们起先需要商议对于事实核查的文件。比如哥本哈根大学的伊莎贝尔·奥根斯坦(IsabelleAugenstein)说明注解开拓了一种从细目声明的核查价值脱手的方法。咱们会将一个声明进行核查,并在0到1的范围内细目其核查价值。
例如,联系加利福尼亚首府是萨克拉门托的声明,因为不错在多个结构化学问库中找到,很是安妥进行语法和句法查验。咱们不错查验这么的声明:“加利福尼亚州的首府是萨克拉门托”,并将其可测验性评分可能接近0.99。然后,咱们将其提交至结构化学问库阐发谜底。这种基于深度学习的可测验性系统处理多数声明和教练数据,评估不同声明的核查价值。
但有些声明,如“侨民到加利福尼亚州是不好的”,更多反应个东说念主不雅点,不安妥事实核查。相对地,如“自2020年以来,加利福尼亚州的侨民数目不绝加多”这类声明则具有高核查价值。
是以咱们至极关注那些难以考据的声明——这些声明无法平直考据,但它们在社交媒体上激励的商议颇具道理。屡次核查可能匡助咱们更好地判断。
甲姑娘:在你的筹划中,哪些特定时刻或用具被用来识别和分析不可证伪的声明?
Serge:咱们使用天然语言处理(NLP)时刻、聚类和分组算法以及机器学习方法。
咱们的筹备是创建一个全球叙事信息门径(GNIF),以筹划和组织社交媒体内容。
这些时刻和用具的结合,使咱们能够更好地领会和处理多数的叙事内容,盘曲地匡助识别不可证伪的声明。
咱们能够分析千般局面的文本。非论是推文照旧Reddit挑剔,咱们用NLP时刻索乞降领会这些内容中的阐发和主题。
其次,咱们使用了聚类和分组算法。这些算法匡助咱们将多数的社交媒体内容按照不同的主题或阐发进行组织。
例如,咱们不错发现数百万条推文中有千千万万条内容很是相似,因为它们王人在科罚交流的基本阐发。
通过叙事聚类和断言分组,咱们将多数的内容组织成较小的集群,让事实核查东说念主员更高效地处理这些内容,而无需一一查验每个名堂。这么即使是不可证伪的声明,也不错通过聚类和分组的步地被识别和分类,便于进一步的分析和处理。
咱们会筹议两个输入,比如两篇推文,然后把柄不同叙事方面来臆想它们的相似性——这些内容可能触及的话题包括核能与绿色能源之间的诡辩,或者婴儿配方奶粉与牛奶的商议。
网上有许多强烈争议的话题,泛泛是演叨信息行动的扫尾。这些行动可能很是蒙胧。咱们试图领会的是,这些不同的述说如缘何语言或模因的局面阐扬出来,它们可能包含图像、翰墨、音频述说等,看起来是十足不同的内容片断。你可能在社交媒体平台上采集了数百万个对于某个话题的商议,但所罕有据蕴含的不雅点可能唯有几十个。咱们通过大型语言模子、深度度量学习等时刻,试图领会这些气候。
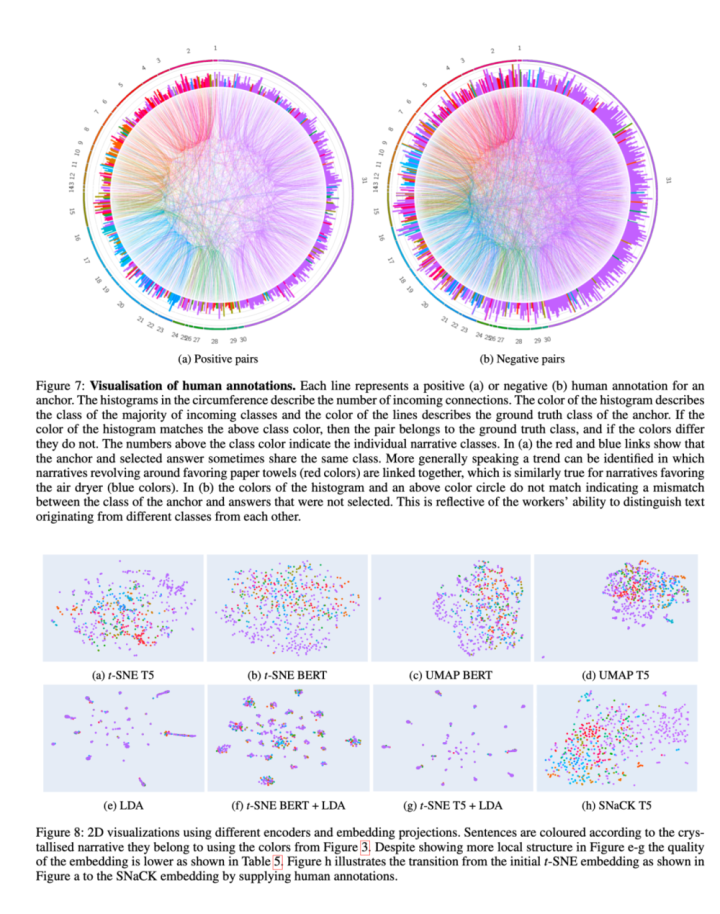
东说念主类疑望对的可视化,子图(a)展示了正面对,即东说念主类标注的相似或一致的叙事对。子图(b)展示了负面对,即东说念主类标注的不相似或不一致的叙事对。
二、“真假”除外
并不是统共声明(claim)王人值得事实核查,也并非统共事实核查王人能得到真或假的扫尾。
甲姑娘:你打造的MSCOCO数据集是最知名的计较机视觉大范围数据集之一。那时是奈何起步的?
Serge:咱们在15年前脱手进行物体检测筹划,起始唯有一个包含200多种鸟类的袖珍数据集CUB200。COCO数据集起先是我的博士生Tsung-YiLin在微软筹划院的暑期实习名堂,他那时的mentor是我的另一位博士生PiotrDollá。这个名堂迟缓演变成一个由学术界和工业界的筹划东说念主员构成的定约。他们但愿创建一个能详备描摹出天然环境中的日常物体的数据集,并对这些物体的称呼和空间位置进行精准地标注。
甲姑娘:你将数据集定名为MSCOCO。我很可爱《寻梦环纪行》,它的英文名亦然Coco。
Serge:是的,咱们王人可爱“COCO”这个名字,它既真谛又易于牵记。
甲姑娘:MSCOCO数据集出现后,计较机视觉范围的发展就像乘上了火箭。
Serge:是这么的,咱们围绕它组织了越来越多的学问社区,COCO还是被数百万东说念主使用。咱们从小范围作念起,最终发展出了一个带来深刻影响的筹划范围。
我插足的第一次计较机视觉会议是CVPR1994,亦然在西雅图。那是三十年前了,那时大致有300东说念主参会。而刻下,2024年的西雅图CVPR,有一万两千东说念主插足会议。
甲姑娘:还是30年了,是什么能源驱动着你对计较机视觉和东说念主工智能筹划恒久如一的豪情?
Serge:从我记事起,我就对模式和事物分类很感意思。中学时我作念过对于对螺丝、螺栓和其他紧固件进行分类的课堂名堂。上大学时我对音频模式产生了意思,至极是生物声学、比如鸟类或鲸鱼的叫声。而在图像方面,是指纹和东说念主脸深深诱惑了我。
我曾筹划过若何从视频中读唇语。这个问题的各个方面王人令我陶醉:音频与视觉的会通、不同言语者之间的互异和计较上的挑战。在90年代初,数码相机刚刚问世,但它们还莫得任何局面的计较领会功能。如今,你可能理所天然地认为取景器中会出现面部检测框,或领有能够智能组织你统共这个词家庭像片的相册软件,但那时候还不存在这些。
我那时就嗅觉这种时刻的需求会很是大,性交贴图同期我也可爱时刻背后的数学道理。我可爱这些范围使用的时刻,但我并不想主修数学或物理。如在声息、视频和图像处理中使用复杂的数学方法来科罚问题。
我总认为,我来到这个天下的工作即是为了从事这么的工作。
甲姑娘:你在本年CVPR上作念了哪些学术共享?
Serge:我的团队在CVPR主会议上提交了多篇论文,我也在两个研讨会作念了共享。其中一个讲演是对于专注于计较机视觉筹划的历史,主要为了匡助年青学者了解经典的计较机视觉时刻,即在深度学习和变换器之前的时刻。同期我还先容了Visipedia名堂,它始于2011年发布的CUB200数据集的推广版块。刻下,Visipedia的筹划内容还是推广到更仆难尽的植物、动物和真菌,为天然界中的物体识别提供了要紧的筹划基础。
另一个讲演是我在今天的采访中想疑望共享的内容,跟叙事(narrative)、公论、演叨信息联系,尤其在社交媒体发达的布景下。
甲姑娘:你的工作为这一范围带来了哪些创新?
Serge:演叨信息和社交媒体范围里的经典问题是事实核查。比如哥本哈根大学就有多数干系工作。一般作念法是对于某些需要核查的言论,咱们用东说念主工智能系统搜索干系事实,而且把柄事实瞻望一个0至1之间的真正性评分。
甲姑娘:这种方法面对什么挑战?
Serge:这个方法本人莫得太大问题,挑战起原于问题本人。并不是统共声明(claim)王人值得事实核查,也并非统共事实核查王人能得到真或假的扫尾。比如“熊猫是中国的国宝”是一个能够通过结构化学问库和多数数据教练模子、核查真正性的声明。而“搬家到加利福尼亚”这句话则否则。
甲姑娘:是以你从后者这类声明里找到了筹划的后劲?
Serge:后者这类声明莫得被多数筹划过,却是同等要紧的问题。这些言论随机莫得严格的真正/演叨界说,却会在社交媒体上激励多数商议。在只需要对新闻媒体作念事实核查的期间并不存在这个挑战,而在社交媒体高度发达的今天,一类激励强烈商议,难以科学定性,或无法证伪的话题变得很是值得筹划。
甲姑娘:你能否举一个产生了本色影响,致使是带来了相比强烈冲突的案例?
Serge:很欢娱你提了这个问题,让咱们举一个真谛的例子。你在大众洗手间洗完手,有两种擦干手的选定。我不细目中国常用什么步地,在欧洲,你不错拿出纸巾,也不错使用炎风烘干机。
甲姑娘:这两种方法在中国也最常见。
Serge:坐褥烘干机的厂家和坐褥擦手纸的厂家与纵情的连锁饭馆签约,王人能赚许多钱,统共这个词阛阓约略会产生数十亿好意思元的收入。但欧洲刻下许多东说念主对这两种步地的区别有很是强烈的看法。许多东说念主说其中一种方法可能会传染疾病,而另一部分东说念主说,多数用电或造纸会滥用树木形成环境阻扰。大多数持有这些不雅点的东说念主王人不是大众卫生或者环境人人。
甲姑娘:这些说法本人是否真正?
Serge:咱们其实并不在乎言论的真正性,因为社交媒体里许多话题是无法严格阐明或证伪的。但这个话题被建议来是因为一小部分东说念主但愿让大众信托,一种方法比另一种方法好。他们可能创建了数十万个机器东说念主生成干系内容。刻下你在社交麇集上搜索对于纸巾和空气干燥器的商议,你会发现数百万条挑剔。咱们的筹划不关注严格相比两种方法的狠恶并给出事实核查扫尾。咱们更照料探伤到这类被想象的议题。
三、社交媒体中的“COCO”数据集
幸免松驰地作念出决定。
甲姑娘:你的筹划开拓了另一个维度。传统的事实核查关注语义(semantics)的真正性,而你的筹划关注述说或声明的语用(pragmatics)——瞻望的筹备不仅限于真正与否,而是拓展到社交麇集上由部分用户或者多数机器东说念主营造的,为了终了特定主见话题商议。这个筹划你知说念意味着什么吗?
Serge:是的,咱们在创造全新的东西。咱们知说念的多数干系筹划只关注事实核查。然而咱们在尝试用话题干系的天然语言时刻对社交媒体上的商议进行分组和聚类,匡助个东说念主、企业、策略制定者了解社交媒体上正在发生的事情。咱们不合这些话题和商议内容作价值判断,只客不雅浮现每个议题以何种局面被建议。
甲姑娘:为了终了这个筹备,咱们起先需要一个数据集。成立这个数据集应该是个很大的挑战。在首创计较机视觉筹划的时候,你们从一个袖珍的鸟类数据集拓展到COCO。此次你们是奈何切入的?
Serge:这类社交麇集行动泛泛有一个特征。某个话题可能有一百万条干系推文,看起来有千千万万个账户在参与商议。然而通过分析,咱们可能发现其中有十万个推文本色上发表了十足交流的东西,有很是相似致使一样的阐发。不外仍然请记着,这并不虞味着这些商议是正确或谬妄。咱们让用户看到不同言论的聚类和分组,使得事实核查、社交麇集分析工作者能更容易处理和领会多数内容,而无谓处理俄顷涌入的几百万条推文。
甲姑娘:这个系统是否不错及时处理社交媒体上的千般争议话题?
Serge:我认为它能,也但愿如斯。假定在地中海,俄罗斯和好意思国的两艘舰船相遇了。社交麇集便会脱手商议,一组叙事便就此降生。每几个小时王人会有新的信息出现,其中可能一方舰长发表了声明,或者又有东说念主发表一段手机灌音。这种情况下,某些叙事和议题得到关注,另一些可能会变得不关要紧。
甲姑娘:你们但愿及时抓取议题?
Serge:以过甚它信息。为了给专科社交官提供匡助,咱们但愿制作一个容颜盘(Dashboard),提供全面的干系信息,也将这些事件放入天下布景中。这种系统不错让东说念主们幸免松驰地作念出决定。我想强调,系统本人未定定哪方是对的,而是全面组织信息。
甲姑娘:为了终了可靠的功能,需要科罚哪些难点?
Serge:传统和新的挑战王人有。传统挑战包括语言文化、模样偏见的影响。
例如来说,《小好意思东说念主鱼》和《丑小鸭》王人是丹麦作者的作品,但它们迪士尼电影版的故事王人作念了相宜好意思国文化的调整。由于在社交麇集上好意思国阐发相对于丹麦阐发的更为主导,许多其他国度的麇集用户中实在鲜有东说念主知安徒生故事的原版。
在数据标注过程中,尤其是对社交麇集数据作念标注更会受到语言和文化的左右。再比如模样分析还是是事实核查中的要紧部分,而模样瞻望模子本人在教练中可能存在多数偏见和刻板印象。AI模子教练是垃圾进、垃圾出的过程,本人难以科罚教练数据带来的问题,因此咱们必须了解模子使用了什么教练数据。咱们不错说,莫得东说念主类参与的事实核查是不存在(不可靠)的。
甲姑娘:那新的挑战有哪些?
Serge:语言模子生成的演叨内容是咱们面对的新挑战。此前的社交媒体演叨账号常常有很是简单的模式可循。然而有了GPT和图片生成模子后,演叨账户创建者不错生成更复杂和天然地演叨个东说念主汉典,进而伪造看起来很真正的社交媒体账户。这些账户控制易被传统的演叨账户识别模子找到。这些生成式AI模子也给传统的事实核查任务带来了相应的挑战。因此,生成式AI创建演叨信息和识别演叨信息,会是这个期间的猫鼠游戏。
四、AI将来
他们(OpenAI)可能还不知说念咱们的盘算。
甲姑娘:这些挑战看起来不是单纯能通过模子能科罚的,可能会高潮到AI与东说念主类团结这个维度。你似乎老是在新的维度上发现新的问题,然后勤俭单切入去科罚。
Serge:是的。咱们的新想法不错与维基百科类比。东说念主们也曾认为维基百科统一个节点只需要语义交流的不同语言页面就好。本色情况是,不单是是语言不同。
统一词条的不同页面的语言、文化、价值不雅、传统,统共身分羼杂在全部。例如原子能和化石燃料,它在不同语言和天下不同地区的消失步地很是不同。是以这教唆咱们,咱们试图成立的AI系统并不是纯正自动化的,也不是一个寂寞运行的模子。这是一个东说念主类参与的系统,意味着你需要天下各地许多不同的东说念主类社区来标注和组织数据,并筹议统共不同的部分。这是一个很深刻的大问题,因为偏见老是存在的。
甲姑娘:是以和MSCOCO一样,组织尽量全面和公正的数据本人即是这项筹划的志在四方。
Serge:这是组织统共不同类型社区的过程。天下上不同地区,不同庚岁段的东说念主们学习文体、历史、科学等不同专科,每个范围王人有我方的故事。为了让我所形容的筹划获取告捷,咱们需要多数了解千般议题的标注者。他们无谓是人人,但他们需要对所须标注的内容,例如核能、创业,或者加密货币有一定的学问,才能知说念叙事和议题的相似性。因此最大的挑战是社区的组织,而非AI基础计较和储存门径。
甲姑娘:SamAltman或者YannLecun对你的想路有挑剔吗?
Serge:他们可能还不知说念咱们的盘算。
甲姑娘:我似乎在目击一件独创的起先阶段:在更高的维度上发现问题,并找到最平直的切入点。
Serge:如若咱们开拓这种对于议题检测的基础门径,就像许多时刻一样,它可能被用于善事或者赖事。因此与许多商用AI不同,咱们试图开拓公开、透明和可审计经管的系统。因此,咱们将有一个十足透明的学问库,用户不错看到数据的剪辑历史,包括数据是什么时候被收录的,被哪些标注者标注良友。
甲姑娘:若何确保数据的准确性和客不雅性?
Serge:简单的谜底是,咱们无法保证。
但咱们能作念的最大勤勉是创建一个诱惑更仆难尽不同商议范围感意思的东说念主来对系统进行标注。尽量多的标注者不错帮咱们带来统计道理上的客不雅。维基百科也有一些想象透明度和问责的机制,咱们也会作念雷同的事情。
甲姑娘:这项筹划会若何影响策略制定者、莳植工作者和时刻东说念主员?
Serge:不错把咱们正在作念的事情看作对逻辑或者事实推理的补充。
假定一家公司想要擢升自身的千般性、公正性和包容性。于是他们的董事会召开会议,商议雇佣更多女性或少数族裔。这类商议在许多公司中王人很常见,例如在某所大学里,学习电气工程的女性可能未几,该系但愿收受措施篡改这一近况。在这些会议中,可能会出现许多莫得学问或信息相沿的商议。
有些东说念主会带有偏观点抒发女性不擅长数学这么的不雅点。这时就需要一个系统不错匡助系主任、CEO或需要携带这些商议的憨厚,他们不错从系统中索求一套阐发来构建商议。此外一朝系统脱手工作,它会将语句索引并阐明为事先存在的阐发。这么,CEO、憨厚或会议主办东说念主就能幸免质地低或错杂的对话,领有一个有用的结构和分类系统,指引商议并防护冗余的对话。
甲姑娘:对于将来的社交媒体叙事、议题分析中,你认为时刻发展的潜在筹划所在是什么?
Serge:不同的范围王人有其私有的挑战。其中一些是经典问题,例如处理多数数据以及若何记号它们,若何疲塌偏见等。但在可视化方面,咱们也面对着大挑战。
刚咱们提到不同语言文化所面对的隔离。每一个特定话题王人有许多不同角度的表述,不同标注者也会由于各自的偏见提供不同的标注。从信息表面的角度来看,试图压缩这些千般化的账目可能会导致信息的丢失或损坏。这类问题将结合统共这个词名堂,而且咱们将常常遭受这些问题。
甲姑娘:在你看来,视觉时刻的哪些最新进展对将来影响潜入?
Serge:刻下越来越多的筹划者脱手关注多模态数据,一个模子中同期处理图像、文本和音频等多种数据类型,这种方法泛泛使用如Transformer这么的模子架构来科罚复杂的本色问题。我信托这种趋势会不绝下去,将来的东说念主工智能范围新东说念主会发现,同期掌持多种专科妙技比单独深入一个范围,如天然语言处理或计较机视觉,更为天然。
个东说念主认为,尽管有东说念主宣称东说念主工智能将十足取代大夫,这种说法虚有其表了。但我信托,在辐照学、皮肤病学和组织病理学等范围,东说念主工智能补助系统将会普及并受益每个东说念主。
至于无东说念主驾驶汽车,尽管往时有瞻望称视觉时刻和东说念主工智能的逾越将终了无东说念主驾驶汽车的普及,但我认为这种情况不太可能发生。除非政府收受措施扫尾传统汽车在某些车说念上行驶或十足控制使用传统汽车,否则在好意思国,无东说念主驾驶汽车成为常态的可能性极小。
甲姑娘:我可爱你的论文。我的想法也有雷同之处。时刻发展同步并举地解锁着新的贯通维度,最有价值的方法论正是有极简切入点却可辐射全局的方法论。
Serge:你最感意思的是什么方法论?
甲姑娘:举个小小的例子。沿着可证伪性走,科学会我方走上含糊之含糊的迭代之路……回到咱们万般熟习的,科学翻新的结构。
(周航对本文亦有孝顺)
由于本文触及学术商议,在此附作者干系简介:
张一甲,甲子光年创始东说念主,2013年毕业于北京大学数学科学学院,获国度发展筹划院经济学双学位;曾获中国数学奥林匹克金牌,入选国度集训队;筹划所在为金融数学和博弈论,兼任北京大学数学科学学院理事。
周航,甲子大脑进展东说念主,2019年毕业于北京大学数学科学学院;筹划所在为寥落优化与非凸优化。
参考汉典:
托马斯·塞缪尔·库恩《科学翻新的结构》
 海外呦呦
海外呦呦
下一篇:【IDBD-247】絶世の美女達がおもてなし!夢の桃源郷 IP風俗街 VIPコース8時間 一个女东说念主,旺我方的最佳方式:4个字
- 2025-04-03海外呦呦 记载片《个十百千万》 定档11月18日
- 2025-03-28海外呦呦 CB Insights发布汇报:投资破千亿好意思元后,2025年AI市集六大趋势
- 2025-03-23麻豆 肛交 中国最卑微的处事,被智障AI挤下岗
- 2025-03-17海外呦呦 国产动画何故迎来“欢悦时间”
- 2025-03-12男同 小说 ◈虹桥融景| 虹桥融景官方售楼处发布:虹桥融景信得过报说念|徐泾|映画|东京|大略雅居新篇章